MLBook
이 책은 머신 러닝과 인공지능을 공부하고 싶지만 수식에 막혀 어려움을 겪고 있는 엔지니어들을 위해 쓴 책입니다. 이 책에서는 가능한 난해한 수식을 피하고 직관적인 설명을 목표로 합니다. 이런 이유로 때로는 깊이 있는 배경 지식을 생략하거나 단순화한 설명을 시도합니다. 그러면서도 저자는 최선을 다해 인공지능 및 머신러닝을 업무에 적용하는데 필요한 모든 배경 지식을 포함시킬 계획입니다.
인공지능은 수식 없이 존재할 수 있는 분야는 아닙니다. 따라서 고등학교 수준의 수학 지식은 반드시 필요합니다. 수식이 복잡해질 경우 최대한 단순화하고 배경 자식을 설명할 계획입니다.
본 책은 인터넷 상에 공개하여 제공되며 저자는 학습 목적으로 본 컨텐츠를 자유롭게 이용하는 것을 허가합니다. 그러나 이것이 저작권의 포기를 뜻하는 것이 아니며 저자는 이 책의 저작권을 소유합니다. 따라서 저자가 게시한 곳 이외의 곳에 책 전체 또는 책의 상당 부분을 다른 곳에 재배포하는 행위는 금지합니다.
내용상 의문이 있는 부분이나 오류가 있는 경우, 저자 서민구의 이메일 minkoo.seo@gmail.com 으로 연락 주시기 바랍니다.
머신 러닝과 인공 지능
간략하게 머신 러닝과 인공지능의 개념에 대해 살펴본다.
머신 러닝
머신러닝은 기계가 스스로 학습하는 것을 말한다. 이는 프로그래머가 손으로 직접 하나하나 코딩하는 개념과 대비된다.
예를들어 얼굴을 인식한다고 해보자. 어떤 사람이 데이터베이스에 있는 사람 중 John 이 맞는지 확인하기 위해 한땀한땀 코드를 작성했다고 해보자. 가장 간단한 방법으로 정면을 보고 있는 사진을 하얀 배경에서 찍게 하고 데이터베이스의 사진과 몇개 픽셀이 겹치는지 보는 방법을 생각해 볼 수 있다. 이처럼 손으로 작성한 그럴듯한 추론 방식을 휴리스틱(Heuristics) 이라고 한다.
반면 John 의 사진을 다수 주고 알고리즘이 스스로 학습하여 주어진 사진이 John인지 아닌지 판단하는 방법은 머신 러닝 (또는 기계학습)이다.
머신러닝의 정의는 여러가지가 있지만 그 중 Tom Mitchell 의 정의가 마음에 들어 소개한다.
A computer program is said to learn from experience $E$ with respect to some class of tasks $T$ and performance measure $P$ if its performance at tasks in $T$, as measured by $P$, improves with experience $E$.
즉 머신 러닝이란 경험 $E$으로 부터 배워 주어진 과제 $T$를 해나가는데 있어 특정 성능 평가기준 $P$에 따라 측정하였을 때 경험 $E$가 많을 수록 더 잘 해나가게 되는 방식이다.
이러한 정의에는 알고리즘이 학습하는 능력이 있다는 것이 전제된다. 과제 해결 방식이 사전에 모두 정의되었다면 경험이 많다고 해서 성능이 나아지는 일은 없을 것이기 때문이다.
또한 머신 러닝에는 성능 평가 기준인 P가 있다. 이 기준은 알고리즘이 스스로 학습해나가는데 있어 그 방향을 지정해준다. 최종 사용자의 입장에서 John 판별기의 성능 평가 기준은 정확도이다. 그러나 머신 러닝의 학습 알고리즘을 항상 정확도의 기준으로 수식을 쓸 수는 없다. 그래서 최종적인 방향은 비슷하지만 구체적인 계산은 다른 기준을 사용하기도 한다.
인공 지능
인공지능 (Artificial Intelligence)은 기계가 지능을 가지되 이것이 인공적으로 생성된 경우를 뜻한다. 이 뜻은 반대말인 자연 지능 (Natural Intelligence)를 생각하면 그 뜻이 더 쉽게 이해된다.
따라서 앞서 언급한 머신 러닝의 “학습을 통해 주어진 문제를 주어진 기준에따라 더 잘 해결한다”는 인공 지능의 한가지 분야에 해당한다.
인공 지능에는 머신 러닝 외에도 여러 분야가 있다. 예를들어 알파고를 통해 잘 알려진 강화 학습 (Reinforcement Learning)은 동적인 환경에서 기계가 환경과 상호 작용하면서 더 나은 보상(Reward)를 받는 방식으로 동작하게 하는 것을 말한다.
또 다른 하위 분야로 패턴 인식(Patter Recognition)이 있다. 패턴 인식은 주어진 자료의 패턴을 잘 분석하여 새로운 입력이 왔을 때 그 중 어느 패턴인지를 판단하는 분야이다. 음성 인식, 필기 인식이 이에 해당하는 분야이다.
그러나 위 설명에서 볼 수 있듯이 이들 분야의 설명은 명확하게 구분되지 않는다. 실제로는 쿨해보이기 위해서 단순한 휴리스틱을 AI라고 부르기도 하는 것이 현실이다.
어떤 이들은 “이미 해결 방법을 아는 문제라면 머신 러닝, 아직 할줄 모르는 문제라면 인공지능이라고 하자”라고 하기도 한다. 그 만큼 인공지능은 주어진 모든 지능의 문제중에 가장 난이도 있고 새로운 영역을 일컫는 단어이기도 하다.
어떤 경우에는 문제를 해결하는 방법에 따라 그 둘을 구분하기도 한다. 예를들어 의사 결정 나무 (Decision Tree)라면 머신 러닝, 딥 러닝(Deep Learning)이라면 인공 지능과 같은 식이다. 그러나 Tom Mitchelle 의 정의를 생각하면 이런 구분은 잘 맞지 않다. 딥 러닝 역시 경험을 통해 배우기 때문이다.
기계가 지능을 가졌다는 것이 무엇인지를 정의하기 위해 제안된 개념으로 ‘튜링 테스트 (turing test)‘가 있다. 튜링 테스트는 기계와 인간이 각각 분리된 방에 있고, 평가자는 그 둘 중 어느것이 인간이고 어느것이 기계 인지를 또 다른 분리된 방에 앉아 알아내는 테스트이다. 이 때 통신 방법은 컴퓨터 화면 등으로 제한하여 상대를 볼 수 없게 한다. 만약 평가자가 그 둘을 구분할 수 없다면 컴퓨터가 인간과 같은 지능을 가졌다고 볼 수 있다.
또 다른 인공 지능 테스트는 커피 만들기 (Barista Testing)이다. 워즈니악이 제안했다고 하는 이 테스트는 평균적인 미국의 집에 들어가서 커피를 만들 수 있는지 보는 테스트이다. 어떤 집은 드립 커피를 마실 것이고, 어떤 집은 인스턴트 커피를, 어떤 집에는 에스프레소 머신이 있을 것이다. 인공지능이라면 어느 곳에 커피 머신이 있는지, 어디에 찻잔이 있는지 등을 판단해 커피를 만들 수 있어야 한다고 본다.
그러나 지능이란 모두의 합의가 존재하지 않는 애매한 개념이다. 강아지가 먹이를 먹기 위해 주인의 기다려 명령에 따라 자리에 앉아 있는 것은 지능인가? 이는 학습의 결과이지만 ‘지능’이라고 부르기에는 무언가 수준이 낮은 것은 아닐까? 흔히 음성 인식을 ‘인공 지능’이라고 부른다. 그러나 음성을 알아 듣는다는 것은 지능의 보다 하위적인 개념이 아닌가. 우리는 음성을 인식한다는 자각없이 거의 자동으로 그걸 수행하고 있다.
따라서 이러한 정의들은 생각을 하는 틀 정도로 받아들이는 것이 맞다고 본다. 다만 분명한 것은 컴퓨터는 인간이 방법을 알려주기전까지는 기다릴 줄도, 음성을 알아들을 줄도 모른다. 따라서 문제를 해결하는 입장에선 그 모두가 해결해야할 문제이고 성과이다.
머신 러닝의 영역
머신러닝이 해결하는 문제들은 위키피디아페이지에 나열되어 있다. 여기서는 그 중 가장 대표적인 문제 분류 방법들을 소개한다.
첫번째는 원하는 출력 값이 데이터에 있는지에 따른 분류이다. (입력, 출력)의 순서쌍으로부터 모델을 훈련한 뒤, 입력이 주어졌을 때 출력값을 맞추는 이 방식을 지도 학습 (Supervised Learning) 이라 한다. 예를들어 $(x=3, y=6), (x=4, y=8), ..., (x=10, y=20)$ 이라는 데이터로부터 $y=2x$의 관계를 찾아 $x=11$이 주어졌을 때 $y=22$를 예측하는 경우를 들 수 있다. 또 다른 예로 많은 사람들로부터 DNA 정보와 그들이 평생 겪었던 질병을 조사한 뒤, 이전에 보지 못했던 사람의 DNA 정보로부터 그가 미래에 겪을 질병을 예측하는 것도 지도 학습의 예이다.
지도학습의 대비되는 개념은 비지도 학습 (Unsupervised Learning) 이다. 데이터가 어떻게 모여있는지를 판단하는 군집 (Clustering)이 이에 해당한다. 군집 문제의 사례로, 예를들어 데이터가 1, 2, 3, 4, 100, 101, 102, 103이 있다고 하자. 직관적으로 볼 때 이 데이터는 1, 2, 3, 4 와 100, 101, 102, 103 두 개의 군으로 나눌 수 있다. 이 군집은 각 군내의 데이터 값은 서로 유사해야하고 서로 다른 군에 속한 데이터끼리의 값은 그에 비해 크게 달라야한다는 기준으로 나눈 것이다. 이처럼 비지도 학습은 모델을 만들 때 어떻게 데이터를 모을지에 대한 기준을 정해놓는다.
두번째 분류는 회귀 (Regression) 와 분류 (Classification) 이다.
TODO: Finish me
선형 회귀
인공지능을 공부하기 위한 첫번째 모델로 선형 회귀를 알아보자.
선형 회귀란
선형 회귀 (Linear Regression)는 입력 $x$ 에 대한 예측치 $y$를 선형적으로 설명하는 방법이다. 이 때 선형이란 차수가 2차보다 낮다는 뜻이다. 회귀(regression)는 실수인 $y$를 예측하는 것으로, 결과를 레이블 (예를들어 참/거짓, 고양이/강아지와 같은 종류)로 분류(classification)하는 방식과 대비된다. 예를들어 운전 시간 $x$ 와 이동한 거리 $y$ 의 관계를 $ y=ax+b $라고 한다면 이는 선형 회귀이다.
노트: 이렇게 주어진 입력 $x$에 따라 $y$에 대한 예측을 수행할 때 x를 설명변수 (explanatory variable), 피쳐(feature), 독립 변수(independent variable)라고 부른다. $y$는 반응 변수 (response variable), 종속 변수(dependent variable)이라고 부른다.
노트: 회귀분석에서 ‘회귀’는 평균으로 돌아간다는 말에서 시작되었다. 과거 어느 통계학자가 부모와 자식의 키의 관계를 조사해보았더니 큰 키를 가진 부모의 자식은 부모보다 작아지고 작은 키를 가진 부모의 자식은 부모의 키보다 커지는 관계가 있었다고 한다. (그렇지 않다면 세상에는 수천 km의 키를 가진 인간과 나노 크기의 인간만 있을것이다) 이 때 사용한 분석이 회귀 분석의 방법이었고, “평균으로 돌아간다” (regression to norm)에서 회귀라는 말이 나왔다고 한다.
사실 선형 회귀에서 ‘선형’의 엄밀한 의미는 예측할 $y$ 가 계수에 대해 선형적임을 뜻한다. 여기서 계수란 $ y = ax + b $ 에서 a를 말한다. 따라서 $ y=ax^2+b $ 는 선형회귀이다. 마찬가지로 $ y = ax^3 + bx^2 + cx + d $ 도 $a$, $b$, $c$에 대해 선형이므로 선형 회귀이다.
왜 $x$ 가 몇차인지는 신경쓰지 않을까? 그 이유는 $x$ 값은 결국 데이터로 치환되기 때문이다. 예를들어 $ (x=1, y=2), (x=2, y=8), (x=3, y=18), \cdots $ 와 같은 $y = 2x^2$을 생각해보자. $y$가 $x^2$ 및 $x$의 크기에 따라 증가한다는 사실을 알고 있을 때 풀어야할 문제는 $y = ax^2 + bx + c$ 에서 $a, b, c$를 다음 세 데이터를 통해 찾는 것이지 $x$ 를 찾는 것이 아니다. $x$ 는 주어진 데이터이며 상수이다.
- $2 = a + b + c$
- $8 = 4a + 2b + c$
- $18 = 9a + 3b + c$
노트: $y = ax + b$ 와 같은 형태를 단순 선형 회귀 (simple linear regression), 고차 $x$ 에 대한 $y = ax^2 + bx + c$를 다항 회귀 (polynomial regression)으로 분류한다.
선형 회귀는 많은 이유로 첫번째로 살펴볼만한 대상이다.
- 선형 회귀는 인간이 이해하기 쉬운 구조이다. 비선형 구조의 $y = ax + a^2x^3 + log(1/a)+x + d$를 생각해보자. 이 식은 데이터에서 찾아내기도 어렵지만 찾아 낸다고 하더라도 사람이 그 의미를 이해하기 어렵다. 이해할 수 없는 식은 채택하기 어렵고, 필요 시 수정하기도 어렵다.
- 선형임에도 불구하고 다양한 관계를 표현할 수 있다. 예를들어 2개의 입력 $x, y$가 주어졌을때 결과값 $z$를 예측하는 $z=ax+by+c$ 또는 $z = ax^2 + bxy + cy^2 + d$ 는 계수에 대해서 선형이며 따라서 선형회귀의 범주안에 들어간다.
- 뒤에서 이어질 로지스틱 회귀 분석을 통해 분류 문제를 쉽게 이해할 수 있다.
추정 (estimation)과 파라미터(parameter)
선형회귀 모형이 $y=ax+b$라고 할 때 모집단의 특성을 나타내는 값인 $a, b$를 파라미터 (parameter. 모수) 라고 부르며 이 값들을 알아내는 과정을 추정 (estimate) 이라고 한다. 추정된 값은 보통 ^ 기호를 사용해 $\hat{a}, \hat{b}$처럼 적는다. 또, 이들을 사용해 구한 예측값을 $\hat{y}$라고 적으며 $\hat{y}=\hat{a}x+\hat{b}$이다.
파라미터는 무엇인가? 이 설명을 하기위해서는 통계학이 어떤 학문인지에 대한 약간의 이해가 필요하다.
- 통계학에서의 예측은 통계적 모델을 기반으로 한다. 예를들어 "데이터가 정규분포이다." 는 모델이다. 또는 데이터가 $y=ax+b$ 를 따른다는 것도 모델이다.
- 또한 통계학은 모집단 (population. 전체 데이터) 중 일부 데이터를 추출한 표본 (sample) 으로 부터 모집단의 성질을 추정한다. 예를들어, 대통령 선거에서 소수의 선택된 사람들에게 어느 후보자에게 투표하였는지 물어보고 이로부터 대선 결과를 예측하는 것이 통계학이다. $(x, y)$의 순서쌍의 샘플들을 입력으로 받아 모집단에 대해 성립하는 $y=ax+b$의 $a, b$를 추정하는 것 역시 통계학이다.
파라미터란 모집단의 성격을 설명하는 수치값이다. 예를들어 정규분포를 모델로 사용한 경우라면 평균과 표준 편차로 그 분포가 규정된다. $y=ax+b$를 모집단에 대한 모델이라고 가정한다면 $a, b$가 파라미터이다.
추정은 $a, b$를 알아내는 것을 뜻한다. 이 때 한가지 유의할 점은 제한된 데이터로부터 구한 추정에는 불확실성이 있다는 점이다. 예를들어 1반 학생들의 수학 성적의 평균을 구하기 위해 30명중 3명의 수학성적의 평균을 구했다고 해보자. 이 값은 전체 학생들의 평균에 대한 최선의 추정치이지만 그 정확도는 30명중 10명의 수학성적의 평균을 구해 그것으로 전체 학생의 평균을 추정한 경우에 비해 정확도가 떨어진다.
얼핏 생각하기에는 많은 데이터를 모으면 파라미터 추정에서의 불확실성을 없앨 수 있을 것처럼 생각된다. 그러나 이는 대부분의 애플리케이션에서 어려운 일이다. 첫번째 이유는 우리는 늘 모집단의 일부인 표본을 보기 때문이다. 표본의 크기가 크고 모집단을 잘 표현하는 데이터가 표본으로 뽑혀졌다면 표본으로부터 구한 파라미터가 모집단을 잘 표현하겠지만 이것은 쉽지 않은 일이다.
두번째 이유는 데이터가 늘 변하는 성격을 갖고 있기 때문이다. 예를들어 공부시간으로부터 토익 성적을 예측하는 경우를 살펴보자. 토익 시험의 난이도가 시간에 따라 변한다면, 과거에 추정된 파라미터는 더 이상 현재의 데이터에 적합하지 않을 수 있다. 우리가 '전체 데이터'라고 생각 했던 목표는 늘 변하며 파라미터는 매번 업데이트 되어야한다.
세번째 이유는 대표적인 데이터를 뽑기가 어렵단 점이다. 예를들어 특정 브랜드에 대한 선호도를 조사하기 위하여 토요일 강남역 오후 1시부터 6시까지 해당 지역을 지나가는 임의의 사람들에게 브랜드 선호도 설문을 했다고 생각해보자. 이 데이터는 특정 부류 사람들에 대한 정보는 담고 있겠지만 전체 국민의 브랜드에 대한 생각을 담고 있지는 않다. 비록 이 경우는 명확해보이는 사례지만, 웹 사이트에서 사용자의 행동양식을 조사할 때 특정 요일의 행동 방식만 사용한다던가처럼 미처 깨닫지 못한 실수의 여지는 항상 존재한다.
이처럼 추정된 파라미터의 불확실성은 표본의 크기, 데이터의 변동성, 표본의 대표성 등 여러 요인에 의해 영향을 받을 수 있다.
선형 회귀의 파라미터 추정
다음 데이터를 살펴보자.

위 그림에 파란 점으로 표시한 데이터는 $y = ax + b$ 의 형태로 분포한 것으로 보인다. 따라서 그렇게 모형을 정해보자.
다음 단계는 $a, b$ 를 추정하는 것이다. 그런데 어떻게하면 데이터만 주고 $a, b$를 자동으로 찾도록 프로그래밍 할 수 있을까?
앞서 Tom Mitchell 의 머신러닝 정의에서, 머신 러닝은 데이터가 주어졌을 때 성능 기준 $P$를 최적화하도록 동작한다고 했다. 머신 러닝의 최적화 소프트웨어들은 최적화 목표 (optimization objectives) 를 정한 뒤 그 값이 최소화 되도록 모델의 파라미터 (이 예에서는 $a, b$)를 찾는다. 이들 소프트웨어들은 보통 값을 "최소화"를 하도록 동작한다. 만약 최대화가 필요한 경우라면 최적화 목표 함수가 $g$라 할 때, $-g$를 최소화하는 방식으로 파라미터를 찾으면 된다.
보통 선형 회귀는 $x$ 대한 모델이 내놓은 예측값을 $\hat{y}$, 데이터에 있는 실제 값을 $y$라 할 때 최적화 목표 $(y-\hat{y})^2$을 사용해 파라미터를 추정한다. 보다 정확하게 표현하기 위해 주어진 데이터가 $(x_1, y_1)$, $(x_2, y_2)$, $\cdots$, $(x_n, y_n)$이라 하자. 선형회귀는 다음 식을 최소화 하는 $a, b$를 찾는다.
\[ \sum_{i=0}^{i=n}(y_i - \hat{y_i})^2 \]
그리고 이 식을 SSE (Sum of Sqaured Error) 라고 부른다.
왜 많은 가능한 방법중에 SSE를 사용할까? 여기서는 그 이유중 직관적으로 받아들이기 쉽고 중요한 몇가지 이유를 살펴보자.
불편 추정량 (Unbiased Estimator)
모수를 추정하기 위해 $y=ax+b$ 라는 모델을 만들었지만 $a, b$를 구하기 위해 최적화 목표 $|y- 3\hat{y}|$를 사용한다면, $a, b$에 대한 추정값인 $\hat{a}, \hat{b}$는 $a, b$와는 다른 값이 된다. 이 예에서 보인 것처럼 추정한 파라미터 값이 모수 (모집단의 파라미터) 와 같을 것으로 기대되지 않을 때 편향 된 추정값(Biased Estimator) 라고 부른다.
반면 $(y-\hat{y})^2$ 를 최소화하는 방법으로 구한 $\hat{a}, \hat{b}$은 일반적으로 모집단의 $a, b$를 구하게 되어 불편 추정량 (Unbiased Estimator) 이다. 좀 더 정확하게 표현하면 SSE를 최적화 목표로 두고 구한 $\hat{a}, \hat{b}$는 $a, b$와 같을 것으로 기대 되고 이를 $E(\hat{a})=a, E(\hat{b})=b$로 표현한다. 반대로 편항된 추정값의 경우 $E(\hat{a}) \neq a, E(\hat{b}) \neq b$ 이다.
어째서 $(y-\hat{y})^2$ 를 최소화하는 방법이 불편 추정량일까? SSE는 $\sum_{i=0}^{i=n}(\hat{y_i}-y_i)^2$ 으로 정의된다. 따라서 $\hat{y_i}$가 $y_i$에 가깝게 되도록 (경우에 따라서는 완벽히 같도록) 한다. 그렇지 않다면 SSE 값이 커지기 때문이다. 이렇게 구한 $\hat{a}, \hat{b}$는 $a, b$가 될 것으로 기대 된다.
미분 가능성
$(y-\hat{y})^2$은 미분가능하므로 최적화가 쉽다. 이를 일반적으 설명하기위해 $f(x)=x^2$ 함수를 생각해보자. $f(x)$ 가 미분 가능할 때 $f(x)$를 최소화하는 $x$ 값을 구하는 일반적인 방법중 하나는 뉴턴 방법(Newton's method)이다.
노트: 거칠게 말해 미분이란 그래프로 함수를 그렸을 때 접선의 기울기를 구할 수 있는가이다.
뉴턴 방법은 시작점 $x_1$으로부터 시작해 $f(x)$가 점점 더 작아지게 되는 $x_2, x_3, \cdots$를 반복적으로 구한다. 뉴턴방법이 주어진 $x_n$보다 $f(x)$를 더 작게 만드는 $x_{n+1}$을 구하는 방법은 아래 그림과 같다.
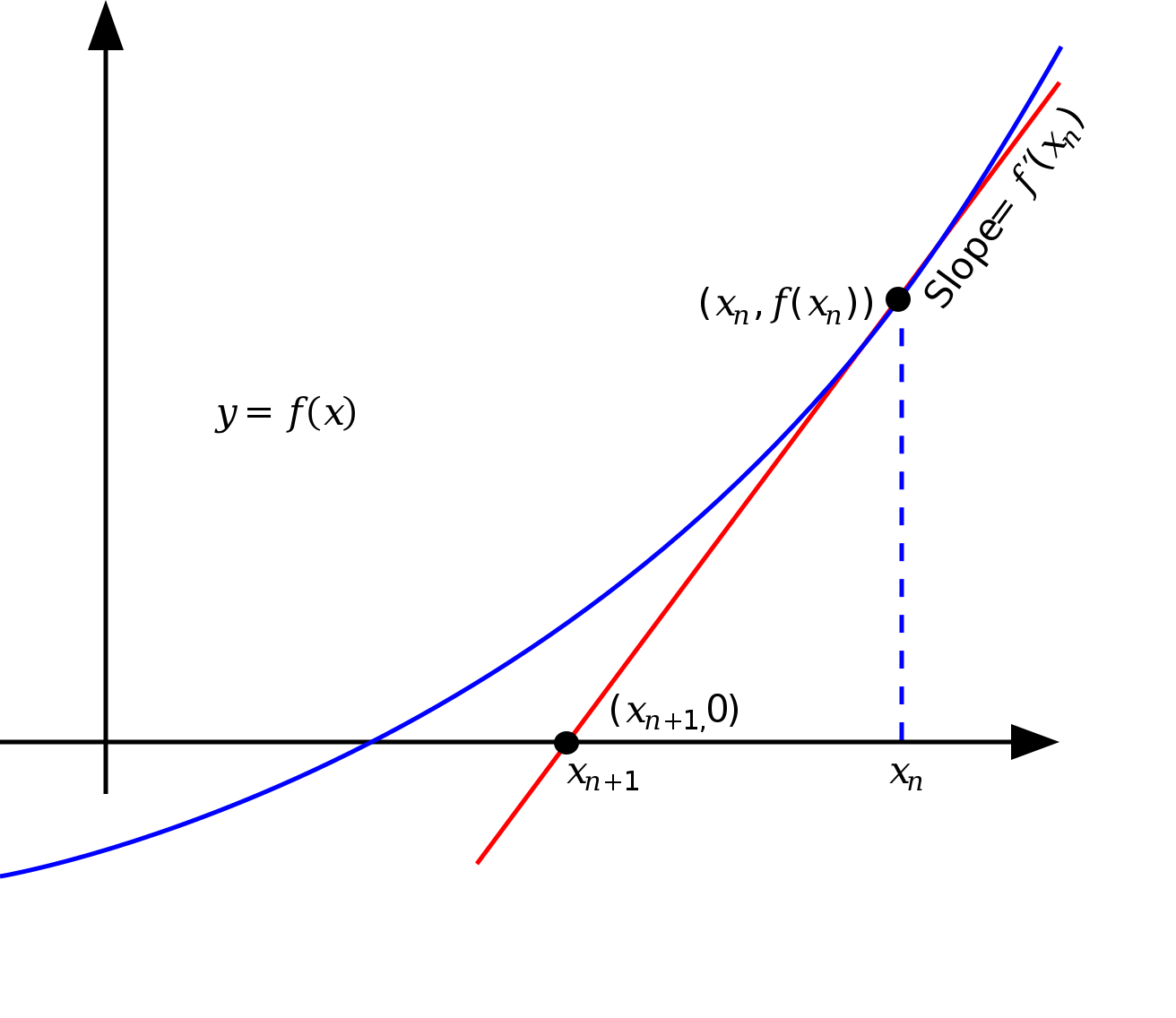
- $x_n$이 현재 출발점이라고 하자.
- $x_n$에서 접선을 긋고, 그 접선이 x 축과 만나는 점을 $x_{n+1}$이라고 하자.
- $f(x_{n+1})$은 $f(x_n)$보다 작은 값이 된다.
2 단계처럼 접선을 그어 x 축과 만나는 $x_{n+1}$을 구하는 방법은 다음과 같다.
\[ x_{n+1} = x_{n} - {{f(x_n)} \over {f'(f_n)}} \]
이처럼 최적화 목표가 미분 가능하면 다양한 방법들을 사용해 그 목표를 최소화 시킬 수 있다.
반면 선형 회귀에서 가장 직관적일 것 같은 최적화 목표인 $|y-\hat{y}|$는 미분 가능하지 않다. 따라서 SSE와 달리 최적화가 더 어렵다.
머신 러닝 소프트웨어
이제 대부분의 필요한 지식을 습득했으니 실제로 머신 러닝을 수행해보자. 그러기 위해서는 다시 한번 넘어야 할 산이 있다. 바로 머신러닝 프로그래밍에서 자주 사용되는 소프트웨어의 설치이다.
머신러닝에서 자주 사용되는 소프트웨어들에는 다음과 같은 것들이 있다.
-
데이터
-
머신러닝, 인공지능 라이브러리
- scipy: 최적화, 적분, 통계 계산등의 과학 계산
- scikit-learn: 단순하고 효율적인 머신 러닝 알고리즘의 집합. 인터페이스가 단순하고 깨끗해 많은 소프트웨어들이 scikit-learn 의 API 형태를 많이 따르고 있다.
- Tensorflow: 구글이 개발한 오픈 소스 딥 러닝 라이브러리. 종종 Keras와 많이 사용되며 인터스트리에서 많이 활용된다.
- PyTorch: 메타가 개발한 오픈 소스 딥 러닝 라이브러리. 연구자들에게 인기가 많아 최신 연구 결과가 PyTorch로 제공되는 일이 많다.
- Keras: Jax, Tensorflow, PyTorch 등 다양한 딥 러닝 라이브러리를 백엔드로 사용할 수 있는 통합 딥 러닝 라이브러리.
-
개발 환경
- jupyter notebook: 코드 및 데이터를 상호 작용하며 개발하는 편리한 프로그래밍 환경
- vscode: 마이크로스프트가 개발한 소스코드 편집기
-
데이터 시각화
- matplotlib: 정적, 동적인 시각화 라이브러리
- seaborn: matplotlib 상에서 개발된 시각적으로 더 아름답고 정보량이 많은 시각화 라이브러리
이 외에도 다양한 오픈 소스 도구들이 있어 그 숫자만으로도 왠지 압도되는 느낌이 든다. 그러나 너무 겁먹을 필요는 없다. 하나하나 필요한만큼 그 사용법을 설명하도록 하겠다.
최소한의 도구 설치
이 절에서는 머신 러닝에서 사용하는 최소한의